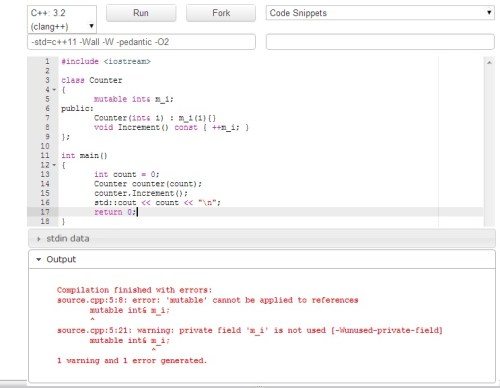
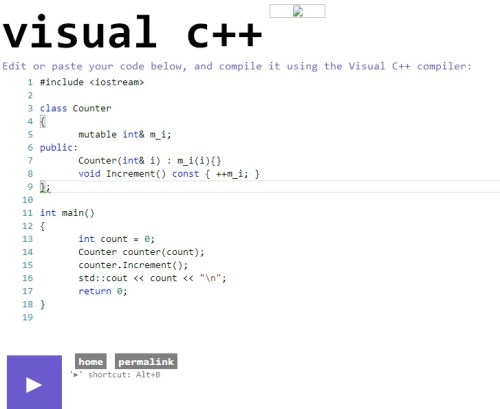
Someone on ISOCpp re-awakened an old question on StackOverflow about noexcept, dynamic v static checking and differences between noexcept and the (now deprecated) throw specifiers.
Throw specifiers were the subject of Item 14 – Use Exception Specifications Judiciously in Scott Meyers’ More Effective C++. The drawbacks he mentions are: the standard prohibits compilers from rejecting calls to functions that might violate the exception specification (including if there is no specifier on the called function – this to allow integration with legacy code libraries that lack such specifications); you cannot know anything about the exceptions thrown by a template’s type parameters – so templates and exception specifications don’t mix; they’re easy to violate inadvertently (e.g. via callback functions); they lead to abrupt program termination when violated.
Stroustrup wrote this about noexcept in his C++11 FAQ:
If a function declared noexcept throws (so that the exception tries to escape the noexcept function) the program is terminated (by a call to terminate()). The call of terminate() cannot rely on objects being in well-defined states (i.e. there is no guarantees that destructors have been invoked, no guaranteed stack unwinding, and no possibility for resuming the program as if no problem had been encountered). This is deliberate and makes noexcept a simple, crude, and very efficient mechanism
This post gives a history of noexcept,
If the noexcept feature appears to you incomplete, prepared in a rush, or in need of improvement, note that all C++ Committee members agree with you. The situation they faced was that a safety problem with throwing move operations was discovered in the last minute and it required a fast solution
There are however important differences [between noexcept and throw()]. In case the no-throw guarantee is violated, noexcept will work faster: it does not need to unwind the stack, and it can stop the unwinding at any moment (e.g., when reaching a catch-all-and-rethrow handler). It will not call std::unexpected. Next, noexcept can be used to express conditional no-throw, like this: noexcept(some-condition)), which is very useful in templates, or to express a may-throw: noexcept(false).
One other non-negligible difference is that noexcept has the potential to become statically checked in the future revisions of C++ standard, whereas throw() is deprecated and may vanish in the future.
and this comment on SO from Jonathan Wakely also makes sense:
template code such as containers can behave differntly based on the presence or absence of noexcept (and equivalently throw()) so it’s not just about compiler optimizations, but also impacts library design and choice of algorithm. The key to doing that is the noexcept operator that allows code to query how throwy an expression is, that’s the new thing, and all that cares about is a yes/no answer, it doesn’t care what type of exception might be thrown, only whether one might be thrown or not